从 k0s 到 Kubernetes:Velero 实战迁移指南
最近的ceph集群使用率已经到了70%了看了一下大部分都是使用不当导致的占用资源倍增,想要全部清理干净就需要搞一下迁移了。
这篇文章就记录一下是如何做k0s集群迁移到k8s集群,当然这个迁移手册也适用于其他的k8s发行版到另外的一个发行版。
需求
最初的k0s集群是处于轻量考虑只部署了一个单节点的,但是实际使用的时候发现cpu利用率很低想要去做cpu超分很麻烦,资源浪费是特别严重的。 出于提高利用率的考量是使用了clonezllia迁移到了一个PVE虚拟机里面,迁移完成释放的节点也重装了一下加入到了当前的PVE集群。
但是这个也带了一个新的问题clonezllia和rsync这种备份恢复不一样,原来的节点是480G的磁盘迁移之后的磁盘是要比原来的磁盘大;rsync是没有这个问题的,可以按照实际的大小来。
由于之前k0s集群是使用的是openebs的hostpathSCStorageClass节点扩容和后续的使用都是问题与其说在原来的基础上折腾不如直接将在此基础上的所有服务迁移到新的k8s集群。
核心需求如下:
- 获得更多的资源
- 迁移之后服务正常
- 迁移之后数据不丢失
velero 简介
velero是一个开源工具,用于安全地备份和恢复、迁移k8s集群的资源以及pvc。
架构和工作流
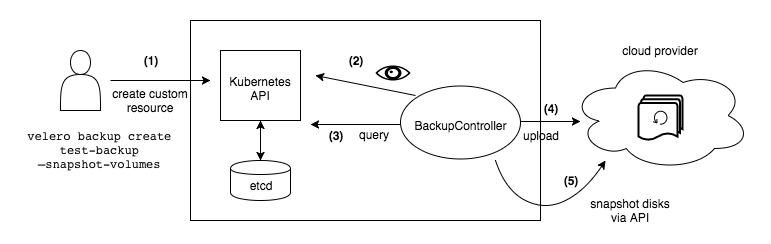
Velero 是非常典型的CS架构(Client/Server),服务端位于目标k8s集群,客户端即本地的cli工具。
Velero 的架构包含一个在 Kubernetes 集群中运行的服务端组件和一个命令行客户端 (CLI)。它利用自定义资源定义 (CRDs),如 Backup、Restore、BackupStorageLocation、VolumeSnapshotLocation、Schedule、PodVolumeBackup、PodVolumeRestore 和 BackupRepository 来管理各项操作。Velero 服务端内的控制器会监视这些 CRD 对象,并执行实际的备份和恢复逻辑。此过程中,Velero 会与 Kubernetes API 服务器交互以发现资源,并与对象存储后端通信以存储备份数据。
环境
当前的k0s节点资源为4c(vCPU)8g(RAM)500G(Disk),版本为:v1.32.2+k0s,新的k8s集群为3master+5worker的组合。
当前k0s的服务如下:
| 服务 | 说明 | 注意点 |
|---|---|---|
| Authentik | 认证服务 | |
| cert-manager | 证书管理 | |
| harbor | 镜像仓库 | |
| ingress-nginx | Ingress | |
| metallb | LB | |
| outline | 文档中心 | |
| mirrors | homelab离线镜像站 | 因为这里用的是local-path 需要直接在新的节点重建后再去拷贝原有的内容到这个pvc |
| pve | PVE 集群反向代理 | |
| haproxy | Ceph rados 负载均衡 | |
| pihole | homelab dns | 此次迁移不包含pihole,而是用coredns作为代替 |
| externaldns | 用于homelab内部dns通讯和解析 | 迁移后对接coredns |
| cloudflared | cloudflare tunnel | 待服务迁移完成之后 |
这些服务都需要完整的迁移到新的k8s集群,并且还要确保这些服务迁移之后还都能正常使用。
⚠️ 迁移注意点 metallb 分配的ip涉及到服务内部dns调用会造成业务中断以及在恢复之前无法使用。
- 集群的cluster name是不一样的 涉及到cluster name变更的需要在搬迁完成pvc之后再去进行单独处理
- velero的备份是要有一个s3的bucket来存放备份一集从这个s3 bucket里面取到对应的文件来进行恢复的。
- 集群的StorageClaas也是不一样的迁移的时候要特别注意
S3我这里是用的ceph的RGW,部署可以参考之前的文章:https://blog.plz.ac/posts/cephadm-deploy/
创建bucket
s3cmd mb s3://homelab-bootstrap-backup
s3cmd mb s3://k8s-backup迁移准备
迁移流程如下
flowchart TD A[准备阶段] A1[验证目标K8s集群可用] A2[部署并配置Velero\n使用Ceph RGW作为备份存储] A3[准备目标集群基础设施:\nMetalLB, Ingress, Cert-Manager] A --> A1 --> A2 --> A3 B[备份阶段(k0s 集群)] B1[暂停关键业务写入\n如 Harbor、Outline] B2[使用 Velero 备份命名空间\n逐个服务执行 velero backup create] B3[确认备份成功\n使用 velero backup get/describe] B --> B1 --> B2 --> B3 C[迁移阶段(K8s 集群)] C1[部署 Velero 并配置 RGW 存储] C2[按顺序恢复基础服务:\nMetalLB -> Ingress -> Cert-Manager -> ExternalDNS] C3[执行 velero restore create 恢复所有服务] C --> C1 --> C2 --> C3 D[后迁移配置] D1[检查 MetalLB 分配 IP 和 DNS 一致性] D2[验证服务状态:kubectl get pods/services] D3[逐个手动验证服务功能\n如 Outline / Harbor / Authentik] D --> D1 --> D2 --> D3 E[收尾阶段] E1[清理无用 Velero 备份] E2[恢复正式业务流量] E3[更新内部文档记录变更] E --> E1 --> E2 --> E3 A --> B --> C --> D --> E
k8s 集群部署
新的k8s集群如下:
| hostname | vcpu | memory | disk | ip | role |
|---|---|---|---|---|---|
| infra-master-1 | 4 | 4 | 40 | 10.31.0.110 | master |
| infra-master-2 | 4 | 4 | 40 | 10.31.0.111 | master |
| infra-master-3 | 4 | 4 | 40 | 10.31.0.112 | master |
| infra-worker-1 | 4 | 8 | 40 | 10.31.0.113 | worker |
| infra-worker-2 | 4 | 8 | 40 | 10.31.0.114 | worker |
| infra-worker-3 | 4 | 8 | 40 | 10.31.0.115 | worker |
| infra-worker-4 | 4 | 8 | 40 | 10.31.0.116 | worker |
| infra-worker-5 | 4 | 8 | 40 | 10.31.0.117 | worker |
安装文档可以参考之前的使用Kubespray离线部署kubernetes
需要开启如下插件:
- ingress-nginx
- cert-manager
- metallb
此外这个集群还会用到两个额外的ip:
- 10.31.0.252 DNS
- 10.31.0.253 ingress lb入口
velero部署
安装velero cli,我这里用的homebrew去安装你可以按照自己的喜好来去安装:
brew install velero创建凭证将AK和SK保存到ceph-credentials-velero文件中,内容如下所示
[default]
aws_access_key_id = xxx
aws_secret_access_key = xxxxx
涉及到的镜像也需要pull到本地来:
docker pull hub.infra.plz.ac/velero/velero:v1.16.1
docker tag hub.infra.plz.ac/velero/velero:v1.16.1 harbor.infra.plz.ac/velero/velero:v1.16.1
docker push harbor.infra.plz.ac/velero/velero:v1.16.1
docker pull hub.infra.plz.ac/velero/velero-plugin-for-aws:v1.12.1
docker tag hub.infra.plz.ac/velero/velero-plugin-for-aws:v1.12.1 harbor.infra.plz.ac/velero/velero-plugin-for-aws:v1.12.1
docker push harbor.infra.plz.ac/velero/velero-plugin-for-aws:v1.12.1安装velero到bootstrap集群
velero install \
--provider aws \
--image harbor.infra.plz.ac/velero/velero:v1.16.1 \
--plugins harbor.infra.plz.ac/velero/velero-plugin-for-aws:v1.12.1 \
--bucket homelab-bootstrap-backup \
--secret-file ./ceph-credentials-velero \
--use-volume-snapshots=false \
--backup-location-config \
checksumAlgorithm="",region=us-east-1,s3ForcePathStyle=true,s3Url=https://s3.infra.plz.ac \
--use-node-agent如果你是用的minio可以参考如下配置:
velero install \
--provider aws \
--image harbor.infra.plz.ac/velero/velero:v1.16.1 \
--plugins harbor.infra.plz.ac/velero/velero-plugin-for-aws:v1.12.1 \
--bucket velero \
--secret-file ./minio-credentials-velero \
--use-volume-snapshots=false \
--backup-location-config \
region=us-east-1,s3ForcePathStyle=true,s3Url=http://10.31.0.5:9000 \
--use-node-agent参数说明:
--provider这里用的是aws可以兼容s3接口的存储如Ceph RGW、Minio等--image因为国内有gfw所以用的cloudflare worker构建的代理仓库去下载--pluginsaws的插件也是要从代理仓库去下载--bucket指定之前所创建的bucket--secret-file指定我们之前所创建的认证凭证--use-volume-snapshots=false不启用卷快照--backup-location-config备份详细的配置checksumAlgorithm=""关闭校验算法用于规避经过代理或者是LB之后出现的XAmzContentSHA256Mismatch问题(如果你的s3Url直接连接的是rgw可以不用加这个`)region=us-east-1ceph的rgw这里可以随意设置一个regions3ForcePathStyle=true:强制使用 path-style 访问(https://s3.infra.plz.ac/bucket),因为虚拟主机风格(bucket.s3.infra.plz.ac)在私有部署中不支持。s3Url=https://s3.infra.plz.ac自建 S3 的 URL,这里用的是经过代理之后的url--use-node-agentvelero的node agent用于支持CSI卷的备份
⚠️ 下面是这个是k0s发行版的问题,如果你是使用的其他的发行版要去确认一下kubelet的目录是在哪里
部署之后发现node agent会失败 还要去手动path一下:
kubectl -n velero patch daemonset node-agent \
--type='json' \
-p='[
{
"op": "replace",
"path": "/spec/template/spec/volumes/0/hostPath/path",
"value": "/var/lib/k0s/kubelet/pods"
},
{
"op": "replace",
"path": "/spec/template/spec/containers/0/volumeMounts/0/mountPath",
"value": "/host_pods"
}
]'
重启pod:
kubectl -n velero delete pod -l name=node-agent
kubectl get pods -n velero这里就能看到patchs之后的pod正常了:
NAME READY STATUS RESTARTS AGE
node-agent-kchfj 1/1 Running 0 51s
velero-7756dd8bc6-8phvc 1/1 Running 0 10m
我们可以创建一个备份来进行测试:
velero backup create test-backup --include-namespaces default查看具体状态:
velero backup describe test-backup --details查看备份日志:
velero backup logs test-backup执行的状态:
kubectl logs -f deployment/velero -n velero删除备份:
velero backup delete test-backup确认是否删除成功了:
velero backup get如果你想要连带着s3里面的内容也删除可以加上--confirm参数:
velero backup delete test-backup --confirm迁移
stoageclass配置
因为这里还会涉及到不同的存储需要单独的写个configmap,用于让velero知道后续的pvc是使用哪个storageclass。
⚠️:这里是要在新的集群去应用不是原来的集群
vi change-sc-config.yaml内容如下:
apiVersion: v1
kind: ConfigMap
metadata:
# ConfigMap 的名称,可以自定义
name: change-sc-config
# 必须是 Velero 的安装命名空间,通常是 'velero'
namespace: velero
# 这个标签是关键,它告诉 Velero 这个 ConfigMap 是用于插件配置的
labels:
velero.io/plugin-config: ""
# 这个标签指定了使用哪个内置的恢复操作插件
velero.io/change-storage-class: RestoreItemAction
data:
# 这里的 key 是旧的 StorageClass 名称
openebs-hostpath: csi-rbd-sc # 这里的 value 是新的 StorageClass 名称
# 如果还有其他的映射需要,可以继续添加,例如:
# another-old-sc: another-new-sc应用:
kubectl apply -f change-sc-config.yaml迁移homelab离线镜像站
备份mirrors-nginx
创建备份:
velero backup create mirrors-nginx-backup --include-namespaces default恢复备份
迁移authentik
备份authentik
velero backup create authentik-backup --default-volumes-to-fs-backup --include-namespaces authentik恢复authentik:
velero restore create authentik-restore --from-backup authentik-backup
# 查看pvc状态是否是bind
kubectl get pvc -n authentik
# 查看
kubectl get pod,svc,ing -n authentik迁移harbor
harbor 备份
velero backup create harbor-backup --default-volumes-to-fs-backup --include-namespaces harbor恢复harbor,这个有点特殊恢复的时候要去扩容一下pvc:
velero restore create harbor-restore --from-backup harbor-backup
kubectl edit pvc harbor-registry -n harbor # 给这个pvc扩容到100G
# 查看pvc状态是否是bind
kubectl get pvc -n harbor
# 查看服务状态
kubectl get pods,svc,ing -n harbor迁移outline
outline 备份
velero backup create outline-backup --default-volumes-to-fs-backup --include-namespaces outline恢复outline:
velero restore create outline-restore --from-backup outline-backup
# 查看pvc状态是否是bind
kubectl get pvc -n outline
# 查看服务状态
kubectl get pods,svc,ing -n outline迁移之后发现了无法正常使用outline上传的问题要去手动修复一下权限的问题:
Error: Permission denied writing to "uploads/e18a9cb4-7088-4c52-a5bd-06305dcf7d12/3171dffb-c75e-48e0-9e47-05134625c6b2/homelab-network.drawio.png". Check the host machine file system permissions.
at /opt/outline/build/plugins/storage/server/api/files.js:47:13
at async apiErrorHandlerMiddleware (/opt/outline/build/server/routes/api/middlewares/apiErrorHandler.js:12:7)
at async apiResponseMiddleware (/opt/outline/build/server/routes/api/middlewares/apiResponse.js:12:5)
at async requestTracerMiddleware (/opt/outline/build/server/middlewares/requestTracer.js:21:5)
at async userAgent (/opt/outline/node_modules/koa-useragent/dist/index.js:12:5)
at async /opt/outline/node_modules/koa-mount/index.js:62:7
at async compressMiddleware (/opt/outline/node_modules/koa-compress/lib/index.js:56:5)
at async logger (/opt/outline/node_modules/koa-logger/index.js:67:7)
迁移cloudflared
vpn 备份
velero backup create vpn-backup --default-volumes-to-fs-backup --include-namespaces vpn恢复vpn:
velero restore create vpn-restore --from-backup vpn-backup
# 查看pvc状态是否是bind
kubectl get pvc -n vpn
# 查看服务状态
kubectl get pods,svc,ing -n vpndns重建
在重建后dns这块是肯定不通的因为原来的pi-hole不在此次的恢复计划内,此次计划是重新使用更为轻量的dns来作为后续的homelab DNS。
新的DNS组合为 coredns + etcd + external-dns
这里单独给一个namespace来跑这些服务:
kubectl create ns dns需要添加如下helm repo:
helm repo add coredns https://coredns.github.io/helm
helm repo add bitnami https://charts.bitnami.com/bitnami
helm repo updatemetallb ip pool
新的集群在部署的时候只是开了插件但是并没有配置可用的ip池子,这里开一下:
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: default-pool
namespace: metallb
spec:
addresses:
- 10.31.0.253/32
- 10.31.0.252/32
---
apiVersion: metallb.io/v1beta1
kind: L2Advertisement
metadata:
name: default-pool
namespace: metallb
spec:
ipAddressPools:
- default-pool⚠️需要注意因为我这里两个ip是原来在k0s集群就已经用到的两个ip 开了之后一定会有冲突,因此要给k0s的节点先关机后再去应用 应用:
kubectl apply -f pool.yaml部署etcd
etcd.vaules.yaml
global:
security:
allowInsecureImages: true
image:
registry: docker-proxy.plz.ac
clusterDomain: infra.homelab
auth:
rbac:
enabled: false
create: false应用:
helm install etcd bitnami/etcd -f values/etcd.values.yaml -n dns查看服务状态:
kubectl get pods,svc -n dns部署coredns
coredns.vaules.yaml
image:
repository: docker-proxy.plz.ac/coredns/coredns
serviceType: LoadBalancer
service:
loadBalancerIP: 10.31.0.252
servers:
- zones:
- zone: .
port: 53
plugins:
- name: errors
- name: health
configBlock: |-
lameduck 10s
- name: ready
- name: kubernetes
parameters: infra.homelab in-addr.arpa
configBlock: |-
pods insecure
fallthrough in-addr.arpa
ttl 30
- name: etcd
configBlock: |-
endpoint http://etcd.dns.svc.infra.homelab:2379
path /skydns
fallthrough
- name: prometheus
parameters: 0.0.0.0:9153
- name: forward
parameters: . 1.1.1.1 8.8.8.8
- name: cache
parameters: 30
- name: loop
- name: reload
- name: loadbalance应用:
helm install coredns coredns/coredns -f values/coredns.values.yaml -n dns查看服务状态:
kubectl get pods,svc -n dns部署external-dns
部署external-dns 可以让k8s 读取之前部署的外部coredns,从而实现说每个服务都可以直接通过外部的dns拿到内网的hosts解析。
对应的yaml:
global:
security:
allowInsecureImages: true
image:
registry: docker-proxy.plz.ac
provider: coredns
policy: upsert-only
txtOwnerId: "homelab"
extraEnvVars:
- name: ETCD_URLS
value: "http://etcd.dns.svc.infra.homelab:2379"
serviceAccount:
create: true
name: "external-dns"
ingressClassFilters:
- nginx
应用:
helm install external-dns bitnami/external-dns -f values/external-dns.values.yaml -n dns
验证dns
可以跑一个临时容器去查询一下内网解析
kubectl run -it --rm --restart=Never --image=harbor.infra.plz.ac/infoblox/dnstools:latest dnstools
添加外部域名
由于我这里设置的external-dns只会过滤名字为nginx的ingresssClaas的域名记录,所以有一些外部的域名是不会有解析的需要手动添加一下解析。
进入到etcd的pod:
kubectl get pods -n dns
kubectl exec -it etcd-0 -n dns -- sh写入记录:
etcdctl put /skydns/ac/plz/infra/s3 '{"host":"10.31.0.7", "ttl":300}'查询:
etcdctl get /skydns/ac/plz/infra/s3验证
nslookup s3.infra.plz.ac 10.31.0.252为了缓存快速生效可以给k8s的coredns 也重启一下:
kubectl rollout restart deployment/coredns -n kube-system
验证
经过验证各个服务都可以正常使用并且没有任何的问题,原来的集群就可以进行销毁了。
重新部署velero
使用不同的bucket:
velero install \
--provider aws \
--image harbor.infra.plz.ac/velero/velero:v1.16.1 \
--plugins harbor.infra.plz.ac/velero/velero-plugin-for-aws:v1.12.1 \
--bucket k8s-backup \
--secret-file ./ceph-credentials-velero \
--use-volume-snapshots=false \
--backup-location-config \
checksumAlgorithm="",region=us-east-1,s3ForcePathStyle=true,s3Url=https://s3.infra.plz.ac \
--use-node-agent定期备份
https://velero.io/docs/v1.16/disaster-case/
创建一个每天早上7点备份的定时计划:
velero schedule create infra-cluster --schedule "0 7 * * *"
查看对应的计划:
velero schedule get
NAME STATUS CREATED SCHEDULE BACKUP TTL LAST BACKUP SELECTOR PAUSED
infra-cluster Enabled 2025-10-02 12:01:37 +0800 CST 0 7 * * * 0s n/a <none> false
多地点备份
可以设置不同的备份路径用于备份到不同的服务器里面去
比如说你可以备份本地的一份,云上一份或者是其他的存储一份这样就可以保障说即使当前的介质已经损坏但是仍然还会有一份备份可以使用。
备份到AWS S3
这里以aws的s3为例子
创建一个名为slchris-homelab-backup-hk的s3bucket,不允许匿名访问。
在IAM控制台,创建单独的IAM访问策略:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:DeleteObject",
"s3:PutObject",
"s3:AbortMultipartUpload",
"s3:ListMultipartUploadParts"
],
"Resource": [
"arn:aws:s3:::slchris-homelab-backup-hk/*"
]
},
{
"Effect": "Allow",
"Action": [
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::slchris-homelab-backup-hk"
]
}
]
}
创建文件velero-aws-credentials用于保存对应的ak、sk,格式如下:
[aws-s3]
aws_access_key_id=<Your-AWS-Access-Key-ID>
aws_secret_access_key=<Your-AWS-Secret-Access-Key>
整合之前的配置:
cat ceph-credentials-velero velero-aws-credentials >> credentials-combined
更新配置:
kubectl create secret generic cloud-credentials \
--namespace velero \
--from-file=cloud=./credentials-combined \
--dry-run=client -o yaml | kubectl apply -f -
重启服务:
kubectl rollout restart deployment/velero -n velero
创建对应的BSL
velero backup-location create aws-s3-remote \
--provider aws \
--bucket slchris-homelab-backup-hk \
--config region=ap-east-1,profile=aws-s3
验证:
velero backup-location get
创建备份:
velero backup create test-backup-to-hk \
--include-namespaces default \
--storage-location aws-s3-remote \
--wait
查看备份:
velero backup get
NAME STATUS ERRORS WARNINGS CREATED EXPIRES STORAGE LOCATION SELECTOR
test-backup Completed 0 0 2025-10-02 13:11:36 +0800 CST 29d default <none>
test-backup-to-hk Completed 0 0 2025-10-02 14:14:47 +0800 CST 29d aws-s3-remote <none>
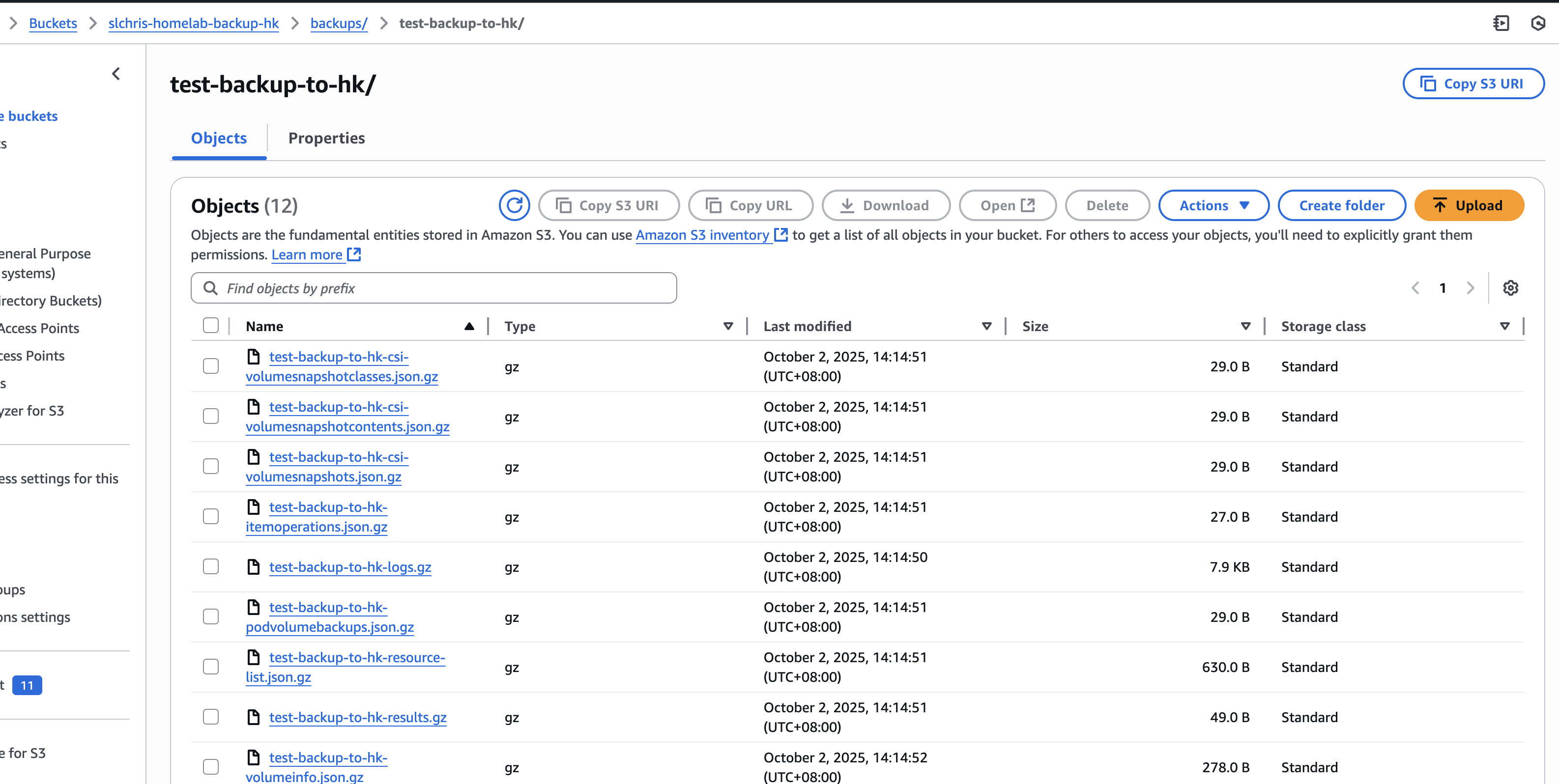
同时也可以在web上看到s3 bucket对应的备份内容:
其他
强制删除
强制删除: 注意这个不会删除实际bucket里面的内容
kubectl delete backup test-backup -n velero --force --grace-period=0强制干掉恢复的任务
kubectl delete restore authentik-backup-20250607214953 -n velero --grace-period=0 --force也可以用patchs的方式:
kubectl patch restore harbor-restore -n velero -p '{"metadata":{"finalizers":null}}' --type=merge卸载
卸载:
velero uninstall总结
velero 这个工具是很好用,但是对于企业来说这么直接手动搞还是有风险的,要多进行测试以及做产品的集成。
如果你觉得这篇文章对你有所帮助,欢迎赞赏~
赞赏